
3D Visual Grounding (3DVG) aims to locate objects in 3D scenes based on textual descriptions, which is essential for applications like augmented reality and robotics. Traditional 3DVG approaches rely on annotated 3D datasets and predefined object categories, limiting scalability and adaptability. To overcome these limitations, we introduce SeeGround, a zero-shot 3DVG framework leveraging 2D Vision-Language Models (VLMs) trained on large-scale 2D data. We propose to represent 3D scenes as a hybrid of query-aligned rendered images and spatially enriched text descriptions, bridging the gap between 3D data and 2D-VLMs input formats. We propose two modules: the Perspective Adaptation Module, which dynamically selects viewpoints for query-relevant image rendering, and the Fusion Alignment Module, which integrates 2D images with 3D spatial descriptions to enhance object localization. Extensive experiments on ScanRefer and Nr3D demonstrate that our approach outperforms existing zero-shot methods by large margins. Notably, we exceed weakly supervised methods and rival some fully supervised ones, outperforming previous SOTA by 7.7% on ScanRefer and 7.1% on Nr3D, showcasing its effectiveness.
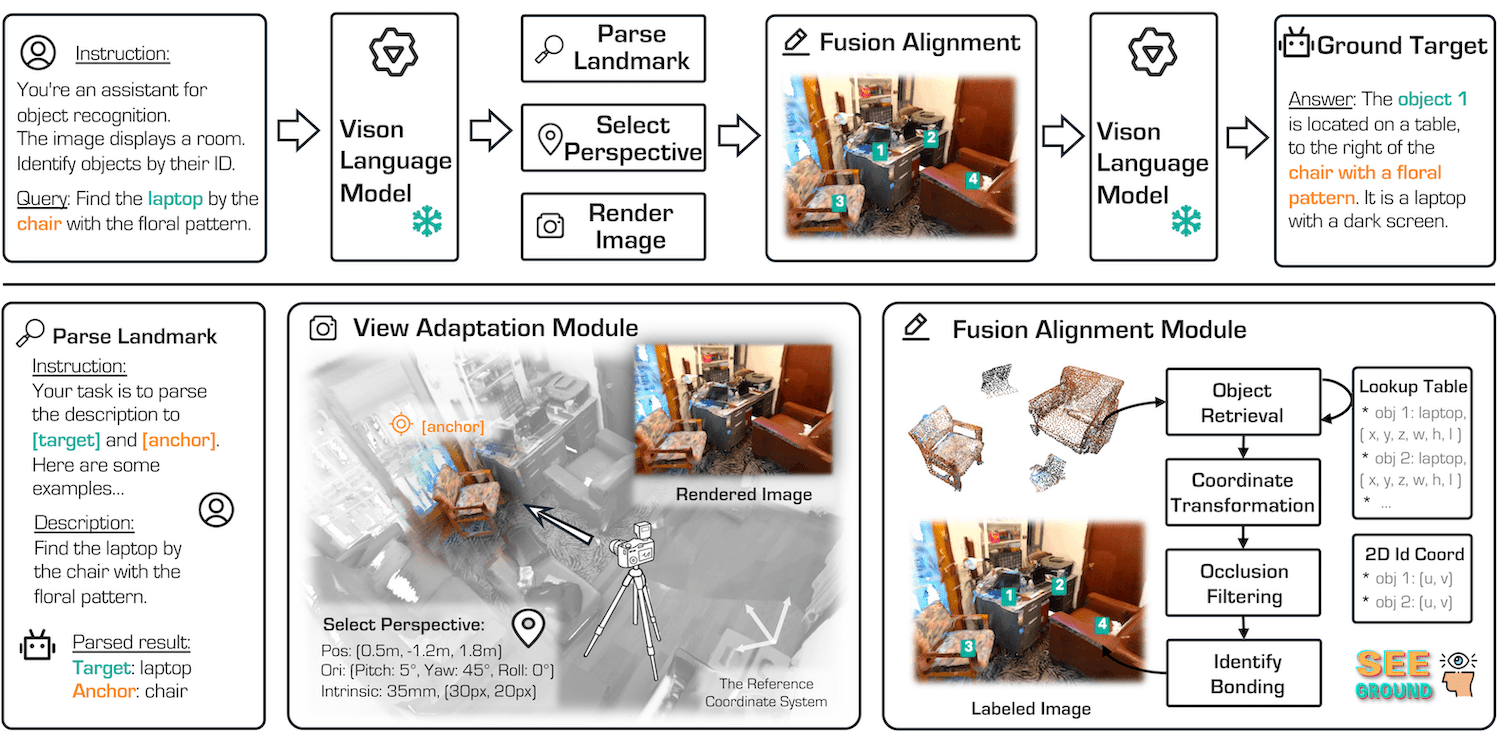
Figure. Overview of the SeeGround framework. We first use a 2D-VLM to interpret the query, identifying both the target object (e.g., "laptop") and a context-providing anchor (e.g., "chair with floral pattern"). A dynamic viewpoint is then selected based on the anchor’s position, enabling the capture of a 2D rendered image that aligns with the query’s spatial requirements. Using the Object Lookup Table (OLT), we retrieve the 3D bounding boxes of relevant objects, project them onto the 2D image, and apply visual prompts to mark visible objects, filtering out occlusions. The image with prompts, along with the spatial descriptions and query, are then input into the 2D-VLM for precise localization of the target object. Finally, the 2D-VLM outputs the target object’s ID, and we retrieve its 3D bounding box from the OLT to provide the final, accurate 3D position in the scene.
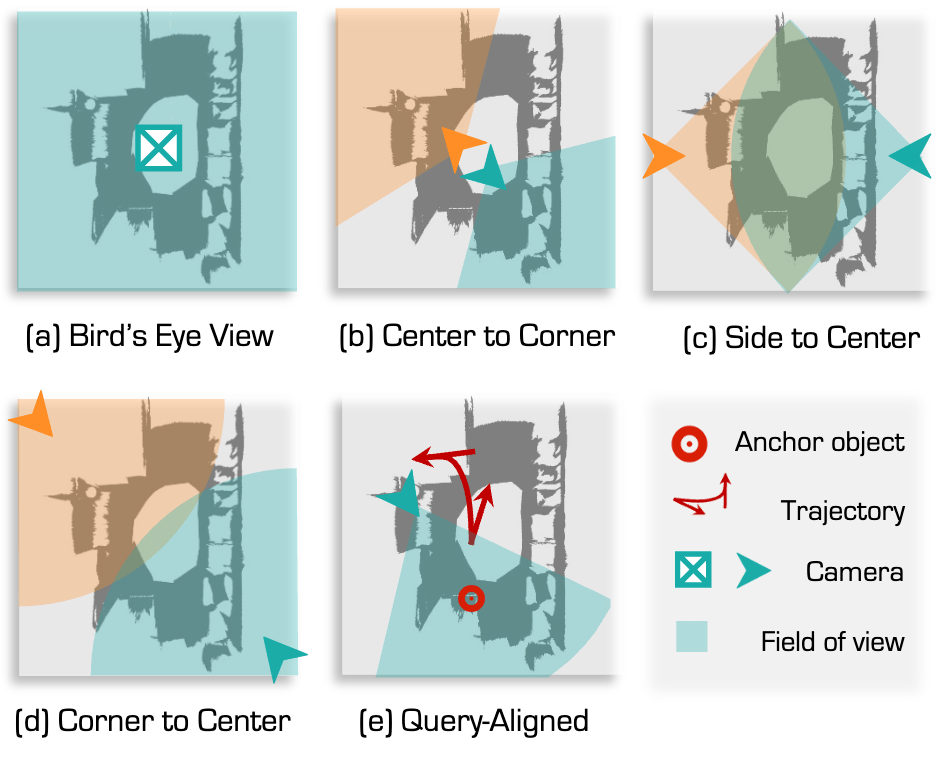
There are many strategies for rendering images from the 3D scene, for instance, LAR positions the camera around each object to capture multi-view images. While this provides detailed views, it lacks overall scene context, making it difficult to interpret relationships between objects. Another is BEV, where the camera is positioned above the scene center, capturing a top-down perspective. Different from existing methods, our “Query-Aligned” strategy dynamically adapts the viewpoint to match the spatial context of the query, enhancing detail and relevance of visible objects compared to static methods.
We provide an analysis of designs on visual prompts, including Mask, Contour, and BBOX.
Each presents unique advantages and limitations, particularly when combined with 3D spatial information.
Mask. It intuitively highlights the entire object surface. However, even with high transparency, it can obscure surface details like texture and fine-grained patterns, which are critical for distinguishing objects.
BBOX. It clearly defines boundaries but introduces visual complexity due to the overlay of bounding box lines. These lines often obscure surface features (colors or textures).
Marker. It offers the most minimal and focused design, marking object centers without introducing visual clutter or occluding appearance features.
This maximally preserves object details like texture and color while providing essential spatial information.

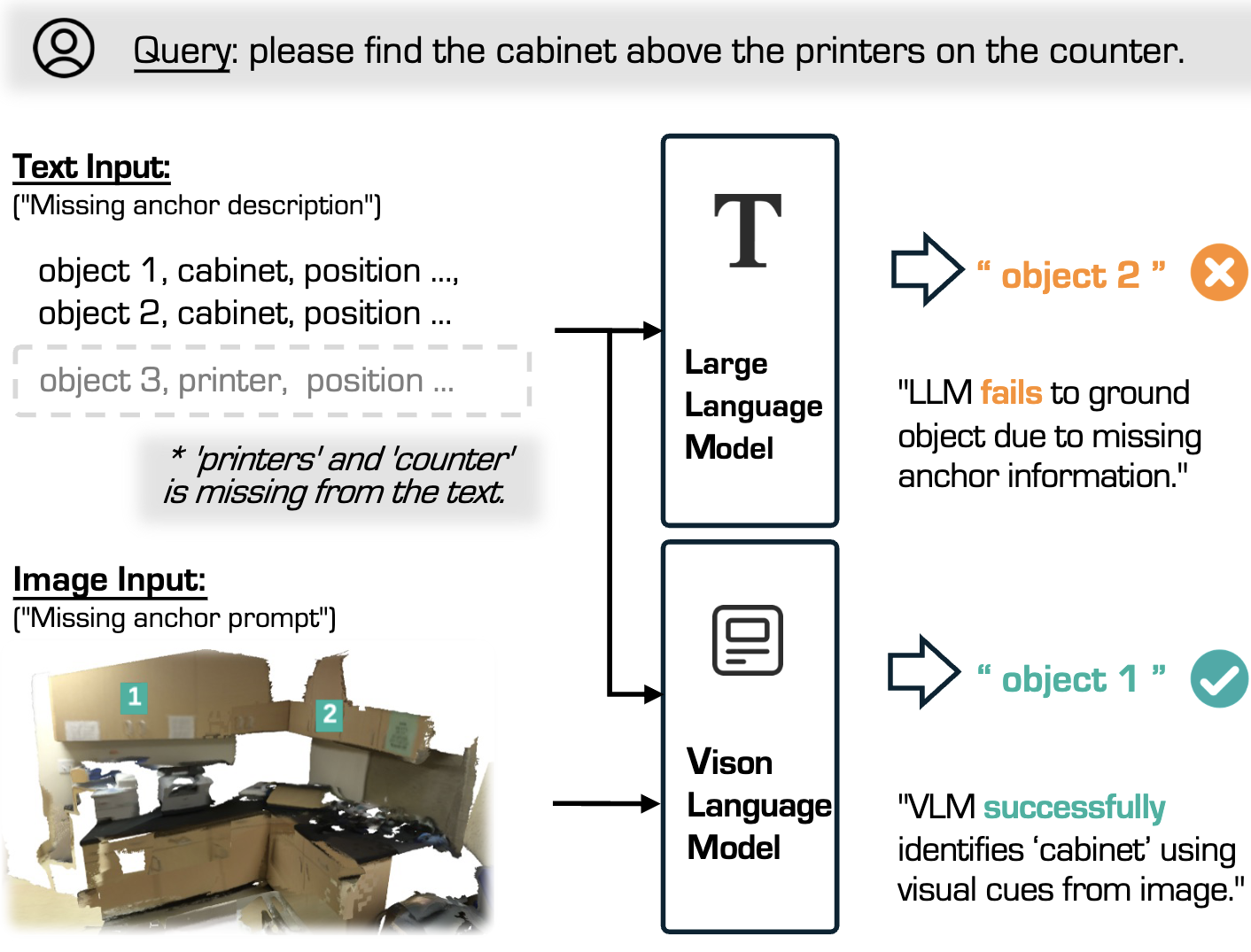
We test the robustness of our approach with incomplete textual information, simulating common misdetection scenarios. By omitting an anchor object from the text while retaining the target, our model uses visual cues to compensate, achieving accurate localization. In contrast, LLM performance degrades without the anchor. These results demonstrate that our method maintains high accuracy with partial text, underscoring the importance of integrating visual and textual data for reliable 3DVG.
"It is the white keyboard, further from the door"
"Whiteboard with four chairs and desk in front of it"
"A red felt office chair with plastic wheels is positioned between a cream chair and a blue chair at the desk furthest from the entrance, facing away from the door"
"There is a laptop on the desk in the corner of the room. The laptop is in front of a single person brown leather armchair"
Here, we presents an interactive 3D room visualization. When a query is selected, the left panel displays an interactive 3D scene where the target object's 3D bounding box is highlighted. The right panel shows the query-aligned 2D rendered image. Users can interact with the 3D scene in the left panel using the following controls:
Interactive 3D Scene
Query-Aligned Image

| Method | Venue | Supervision | Agent | Unique | Multiple | Overall | |||
|---|---|---|---|---|---|---|---|---|---|
| Acc@0.25 | Acc@0.5 | Acc@0.25 | Acc@0.5 | Acc@0.25 | Acc@0.5 | ||||
| ScanRefer | ECCV'20 | Fully | - | 67.6 | 46.2 | 32.1 | 21.3 | 39.0 | 26.1 |
| InstanceRefer | ICCV'21 | Fully | - | 77.5 | 66.8 | 31.3 | 24.8 | 40.2 | 32.9 |
| 3DVG-Transformer | ICCV'21 | Fully | - | 77.2 | 58.5 | 38.4 | 28.7 | 45.9 | 34.5 |
| BUTD-DETR | ECCV'22 | Fully | - | 84.2 | 66.3 | 46.6 | 35.1 | 52.2 | 39.8 |
| EDA | CVPR'23 | Fully | - | 85.8 | 68.6 | 49.1 | 37.6 | 54.6 | 42.3 |
| 3D-VisTA | ICCV'23 | Fully | - | 81.6 | 75.1 | 43.7 | 39.1 | 50.6 | 45.8 |
| G3-LQ | CVPR'24 | Fully | - | 88.6 | 73.3 | 50.2 | 39.7 | 56.0 | 44.7 |
| MCLN | ECCV'24 | Fully | - | 86.9 | 72.7 | 52.0 | 40.8 | 57.2 | 45.7 |
| ConcreteNet | ECCV'24 | Fully | - | 86.4 | 82.1 | 42.4 | 38.4 | 50.6 | 46.5 |
| WS-3DVG | ICCV'23 | Weakly | - | - | - | - | - | 27.4 | 22.0 |
| LERF | ICCV'23 | Zero-Shot | CLIP | - | - | - | - | 4.8 | 0.9 |
| OpenScene | CVPR'23 | Zero-Shot | CLIP | 20.1 | 13.1 | 11.1 | 4.4 | 13.2 | 6.5 |
| LLM-G | ICRA'24 | Zero-Shot | GPT-3.5 | - | - | - | - | 14.3 | 4.7 |
| LLM-G | ICRA'24 | Zero-Shot | GPT-4 turbo | - | - | - | - | 17.1 | 5.3 |
| ZSVG3D | CVPR'24 | Zero-Shot | GPT-4 turbo | 63.8 | 58.4 | 27.7 | 24.6 | 36.4 | 32.7 |
| SeeGround | Ours | Zero-Shot | Qwen2-VL-72b | 75.7 | 68.9 | 34.0 | 30.0 | 44.1 | 39.4 |
| Method | Venue | Easy | Hard | Dependent | Independent | Overall |
|---|---|---|---|---|---|---|
| Supervision: Fully Supervised 3DVG | ||||||
| ReferIt3DNet | ECCV'20 | 43.6 | 27.9 | 32.5 | 37.1 | 35.6 |
| TGNN | AAAI'21 | 44.2 | 30.6 | 35.8 | 38.0 | 37.3 |
| InstanceRefer | ICCV'21 | 46.0 | 31.8 | 34.5 | 41.9 | 38.8 |
| 3DVG-Transformer | ICCV'2 | 48.5 | 34.8 | 34.8 | 43.7 | 40.8 |
| BUTD-DETR | ECCV'22 | 60.7 | 48.4 | 46.0 | 58.0 | 54.6 |
| Supervision: Weakly Supervised 3DVG | ||||||
| WS-3DVG | ICCV'23 | 27.3 | 18.0 | 21.6 | 22.9 | 22.5 |
| Supervision: Zero-Shot 3DVG | ||||||
| ZSVG3D | CVPR'24 | 46.5 | 31.7 | 36.8 | 40.0 | 39.0 |
| SeeGround | Ours | 54.5 | 38.3 | 42.3 | 48.2 | 46.1 |

@inproceedings{li2025seeground,
title = {SeeGround: See and Ground for Zero-Shot Open-Vocabulary 3D Visual Grounding},
author = {Rong Li and Shijie Li and Lingdong Kong and Xulei Yang and Junwei Liang},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2025},
}There are some other excellent works that were introduced around the same time as ours:
- VLM-Grounder: A VLM Agent for Zero-Shot 3D Visual Grounding
- Solving Zero-Shot 3D Visual Grounding as Constraint Satisfaction Problems
- ViewInfer3D: 3D Visual Grounding based on Embodied Viewpoint Inference